研究分野の概略
情報検索としてのデータ圧縮
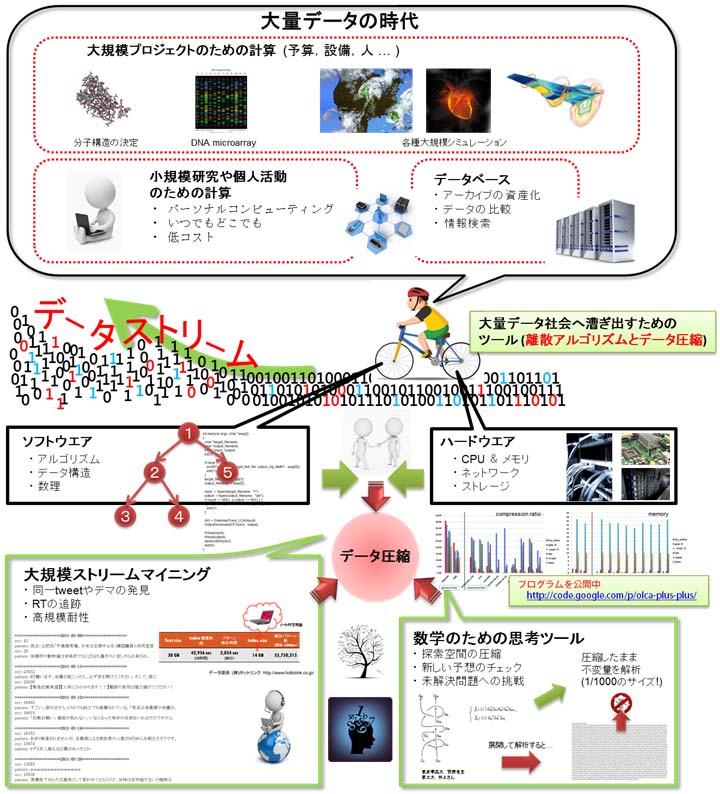
データ圧縮は次世代の情報検索技術になり得ます。
私の研究室では、巨大なテキストデータに対するデータマイニングやパターン検索をデータ圧縮によって実現しようとしています。
例えば、東日本大震災時のtwitterでのつぶやきは数百GBにもなりこのクラスのデータになると情報検索のために特別な技術が必要です。
私たちがウェブから素早く情報を見つけることができるのは、ページ同士を結ぶリンク構造から重要度を計算したり、
キーワード検索の準備を事前にしているからですが、明示的なリンク構造を持たないテキストデータではそのような前処理が困難です。
私たちはこれらの問題を究極のデータ圧縮によって解決しようとしています。
この技術は通常のデータ圧縮と違い、不要な情報を自動的に削除したり重要情報をまとめて取り出すことが可能で、
しかも、そのために圧縮データを復号する必要もありません。
また最近の成果によって、データを圧縮することで情報検索のスピードも高速化できることがわかってきました。
このような技術によって、これまでは困難であった遺伝子データ全体の比較による生物の進化の解析や科学技術文献から類似技術の抽出、
文書やプログラムソースの改竄箇所の特定など様々な応用が期待できます。
劣線形領域圧縮アルゴリズム
ただいま作成中です

ストリーム圧縮技術
ただいま作成中です